GPT-5.5: Khi OpenAI không còn chạy đua vũ trang bằng "cơ bắp"
Sáng nay, OpenAI đã làm rung chuyển cộng đồng công nghệ khi công bố GPT-5.5. Nhưng khác với những lần ra mắt trước đây vốn tập trung vào việc mô hình "to" hơn bao nhiêu hay có bao nhiêu tỷ tham số, tâm điểm của GPT-5.5 lại nằm ở một từ duy nhất: Hiệu quả (Efficiency). Đây không chỉ là một bản nâng cấp phần mềm; đó là một tuyên ngôn về việc AI bắt đầu tự tối ưu hóa chính nó để phá vỡ giới hạn về tài nguyên phần cứng.
Kỷ nguyên của sự tinh gọn: Ít token hơn, thông minh hơn
Trong nhiều năm, cuộc đua AI được mặc định là cuộc đua về quy mô. Càng nhiều dữ liệu, càng nhiều compute, mô hình càng giỏi. Tuy nhiên, GPT-5.5 đang chứng minh điều ngược lại. OpenAI khẳng định rằng mô hình mới này đạt điểm số cao hơn đáng kể so với người tiền nhiệm trong khi tiêu tốn ít tài nguyên hơn.
"GPT-5.5 improves on GPT-5.4’s scores while using fewer tokens."
Sự khác biệt này trở nên rõ rệt khi đặt cạnh đối thủ trực tiếp nhất: Anthropic Opus 4.7. Theo các dữ liệu thực tế từ Artificial Intelligence Index, khoảng cách về hiệu quả sử dụng token là một cú sốc đối với ngành công nghiệp.
"For a 56.7 score on the Artificial Intelligence Index, GPT 5.5 used 22m output tokens. For a score of 57, Opus 4.7 used 111m output tokens."
Phép tính đơn giản cho thấy GPT-5.5 chỉ cần khoảng 1/5 lượng token để đạt được mức độ thông minh tương đương đối thủ. Điều này không chỉ giúp giảm chi phí cho người dùng mà còn giảm bớt áp lực khổng lồ lên các trung tâm dữ liệu đang quá tải.
Codex: Khi AI tự sửa lỗi cho chính hạ tầng của mình
Điểm gây kinh ngạc nhất trong thông báo của OpenAI không nằm ở khả năng ngôn ngữ, mà ở cách họ sử dụng Codex — nhánh AI chuyên về lập trình — để tự tối ưu hóa hạ tầng chạy GPT-5.5. Thay vì chờ đợi các kỹ sư tối ưu hóa mã nguồn thủ công, OpenAI đã để Codex trực tiếp tham gia vào quá trình vận hành.
"To better utilize GPUs, Codex analyzed weeks’ worth of production traffic patterns and wrote custom heuristic algorithms to optimally partition and balance work. The effort had an outsized impact, increasing token generation speeds by over 20%."
Việc một thực thể AI tự phân tích các mô hình lưu lượng truy cập và viết lại các thuật toán heuristic để phân bổ tải GPU là một bước tiến gần hơn tới khái niệm AI tự cải thiện (Self-improving AI). Đây là câu trả lời trực tiếp cho bài toán thiếu hụt chip và chi phí vận hành tăng vọt mà OpenAI đang phải đối mặt.
Những vết nứt trên bảng vàng Benchmark
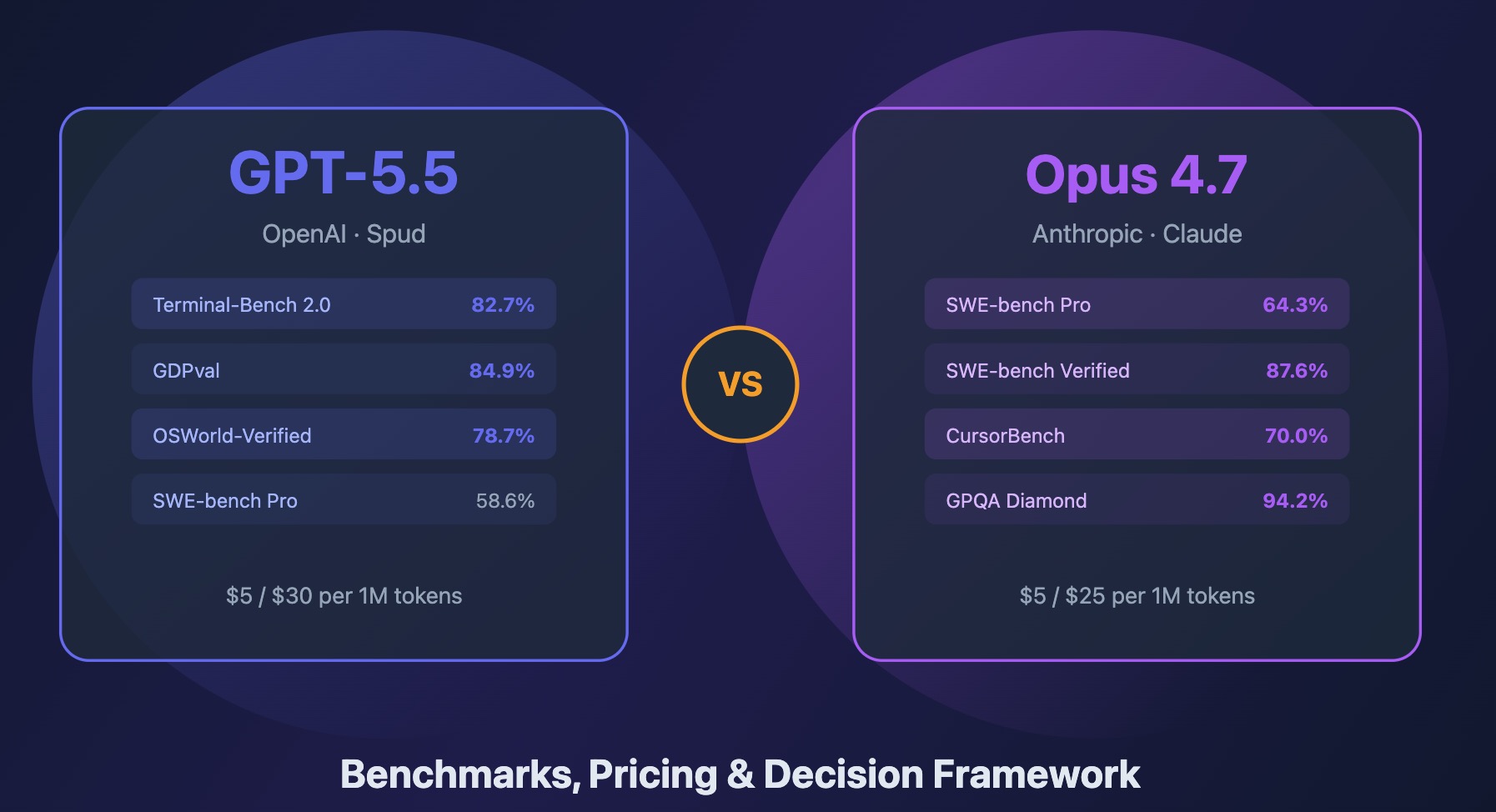
Dù sở hữu những con số hào nhoáng, GPT-5.5 không phải là một vị thần toàn năng. Trong các bài kiểm tra kỹ thuật thuần túy, mô hình này cho thấy sự phân hóa rõ rệt. Nó cực kỳ xuất sắc trong các tác vụ tương tác hệ thống, đạt 82.7% trên Terminal Bench và 81.8% trên CyberGym — những con số tiệm cận mức hoàn hảo.
Tuy nhiên, khi đối mặt với thực tế phát triển phần mềm phức tạp, GPT-5.5 lại cho thấy sự hụt hơi so với đối thủ từ Anthropic.
"SWE-Bench Pro only a slight improvement (57.7% -> 58.6%) while Opus 4.7 hit 64.3%."
Khoảng cách hơn 5% tại SWE-Bench Pro cho thấy dù GPT-5.5 rất nhanh và hiệu quả, nhưng khả năng giải quyết các vấn đề kỹ thuật có cấu trúc sâu (deeply structured software engineering) vẫn chưa thể vượt qua được "vibe" chính xác của dòng Opus. Điều này đặt ra câu hỏi: Liệu OpenAI có đang quá ưu tiên cho các benchmark có thể tối ưu hóa bằng RLVR (Reinforcement Learning from Verifiable Rewards) thay vì khả năng suy luận cốt lõi?
Nghịch lý Solow và câu hỏi về giá trị thực
Giữa những làn sóng tung hô, những tiếng nói hoài nghi về giá trị kinh tế thực sự của AI vẫn vang lên. Một số chuyên gia nhắc lại "Nghịch lý năng suất của Solow" — một quan sát từ thập niên 80 cho thấy sự bùng nổ của CNTT không thực sự làm tăng năng suất lao động tương xứng.
"Because software and 'information technology' generally didn't increase productivity over the past 30 years... Information technology is mostly entertainment, and rather than making you more productive, it distracts you and makes you more lazy."
Lập luận này cho rằng nếu AI chỉ dừng lại ở việc tạo ra các chatbot thông minh hơn hay những trò chơi 3D nhanh hơn (như bản demo 3D Dungeon Arena mà GPT-5.5 vừa trình diễn), thì nó có thể chỉ là một công cụ giải trí cao cấp thay vì một động cơ tăng trưởng kinh tế. GPT-5.5 có thể thắng trên các bảng xếp hạng Arena, nhưng chiến thắng đó có ý nghĩa gì nếu nó không giúp các kỹ sư viết code nhanh hơn hay các doanh nghiệp vận hành hiệu quả hơn?
OpenAI đã đưa ra câu trả lời bằng mức giá: $5 cho 1 triệu token đầu vào và $30 cho 1 triệu token đầu ra. Một mức giá không hề rẻ, phản ánh sự tự tin của họ vào giá trị mà "trí thông minh tinh gọn" mang lại. Cuộc đua giờ đây không còn là ai có mô hình lớn nhất, mà là ai có thể cung cấp trí thông minh với cái giá rẻ nhất và tốc độ nhanh nhất. GPT-5.5 đã đặt cược tất cả vào hiệu năng, và thế giới đang chờ xem liệu canh bạc này có mang lại một cuộc cách mạng năng suất thực sự hay không.